Virtual Assistant
How do I make a Virtual Assistant in Python!?
Well well well, Worry not, because Google just launched Gemini!!!
I will show you how to make how to make a virtual assistant in Python!!
but first, let’s install Python!
Go to Python’s official website and download the latest version of Python. Follow the installation instructions for your operating system. Make sure you tick the download pip option.
Once Python is installed, you can verify the installation by opening a terminal or command prompt and typing:
python --version
Now that pyton is out of the way, let’s work on the virtual assistant. First of all, choose a name for your virtual assistant. I’ll name mine AI MondayAI. Second of all, let’s download Gemini python module. For that, go to the terminal and type:
pip install -q -U google-generativeai
Now, let’s get the Gemini’s API key. For that, go to Google’s makersuite website.
 You may also experiment with so many tools given there. Honestly, it looks so cool!
But before that, let’s complete what we started.
Under API keys, click the “Create API key in new project” button.
You may also experiment with so many tools given there. Honestly, it looks so cool!
But before that, let’s complete what we started.
Under API keys, click the “Create API key in new project” button.
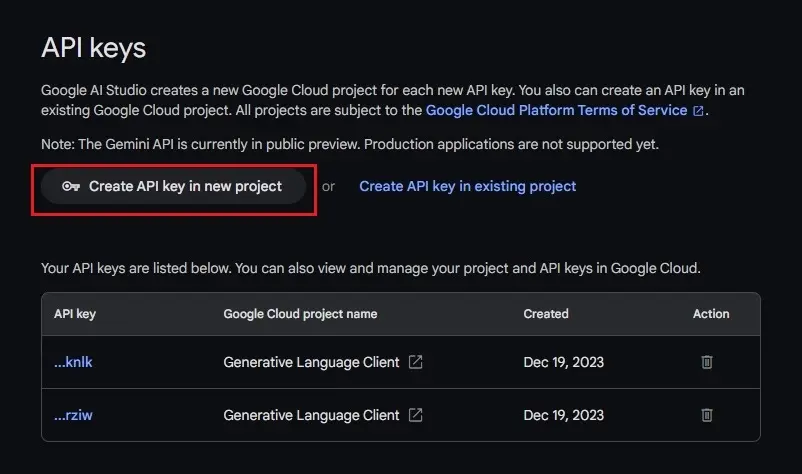
Copy the API key and keep it private. Do not publish or share the API key publicly.
And that’s it! You have gotten yourself the gemini API key!
Now for the most interesting part: THE AI!!! (or maybe MondayAI or whatever you called your AI)
Go to your favourite code editor (I personally like Visual Studio Code), and paste this code:
import google.generativeai as genai
genai.configure(api_key='PASTE YOUR API KEY HERE')
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("What is the meaning of life?")
print(response.text)
First, paste your API key and then run your file. It should give you the result. But, it’s not good enought for us, for let’s modify it! First of all, it should be able to hear our voices, so we will use the speech_recognition module Install it by typing in the terminal:
pip install speech_recognition
Now, import it into your file.
import google.generativeai as genai
import speech_recognition as sr
We will create a function for this, so that we don’t have to write it again and again.
def recognize_speech():
recognizer = sr.Recognizer()
with sr.Microphone() as source:
print("Say something:")
recognizer.adjust_for_ambient_noise(source)
audio = recognizer.listen(source)
try:
print("Recognizing...")
user_input = recognizer.recognize_google(audio)
print("You said:", user_input)
return user_input
except sr.UnknownValueError:
print("Sorry, I could not understand your audio.")
return None
except sr.RequestError as e:
print(f"Error making the request; {e}")
return None
Also on a side note, we will also create a function for sending request to Gemini’s server using the API key.
def generate_response(user_input):
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(user_input)
return response.text
So, the entire code will be,
# Import necessary modules
import google.generativeai as genai
import speech_recognition as sr
# Configure Gemini API key
genai.configure(api_key='PASTE YOUR API KEY HERE')
# Function to recognize speech
def recognize_speech():
recognizer = sr.Recognizer()
with sr.Microphone() as source:
print("Say something:")
recognizer.adjust_for_ambient_noise(source)
audio = recognizer.listen(source)
try:
print("Recognizing...")
user_input = recognizer.recognize_google(audio)
print("You said:", user_input)
return user_input
except sr.UnknownValueError:
print("Sorry, I could not understand your audio.")
return None
except sr.RequestError as e:
print(f"Error making the request; {e}")
return None
# Function to generate response
def generate_response(user_input):
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(user_input)
return response.text
if __name__ == "__main__":
# Recognize speech and generate response
while True:
print("\nListening...")
user_input = recognize_speech()
if user_input:
response_text = generate_response(user_input)
print("AI MondayAI:", response_text)
BUT WAIT! Why stop here, when we can do more? Let’s make something more out of it, maybe making the AI say the response out loud? Maybe, thats a good idea!! For that, you need to install a python module called ✨PYTTSX3✨ (lol)
pip install pyttsx3
And, it’s very easy to add in our already made code!
First, import the module
import pyttsx3
Then, make a function so that we dont have to repeat the same code again and again.
def speak(text):
engine = pyttsx3.init()
engine.setProperty('rate', 150) # Adjust the speaking rate if needed
engine.say(text)
engine.runAndWait()
And Lastly, make some changes at
if __name__ == "__main__":
# Recognize speech, generate response, and speak
while True:
print("\nListening...")
user_input = recognize_speech()
if user_input:
response_text = generate_response(user_input)
print("AI MondayAI:", response_text)
# Speak the response
speak(response_text)
And that’s it! Entire code:
import google.generativeai as genai
import speech_recognition as sr
import pyttsx3
# Configure Gemini API key
genai.configure(api_key='PASTE YOUR API KEY HERE')
# Function to recognize speech
def recognize_speech():
recognizer = sr.Recognizer()
with sr.Microphone() as source:
print("Say something:")
recognizer.adjust_for_ambient_noise(source)
audio = recognizer.listen(source)
try:
print("Recognizing...")
user_input = recognizer.recognize_google(audio)
print("You said:", user_input)
return user_input
except sr.UnknownValueError:
print("Sorry, I could not understand your audio.")
return None
except sr.RequestError as e:
print(f"Error making the request; {e}")
return None
# Function to generate response
def generate_response(user_input):
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(user_input)
return response.text
# Function to speak the response
def speak(text):
engine = pyttsx3.init()
engine.setProperty('rate', 150) # Adjust the speaking rate if needed
engine.say(text)
engine.runAndWait()
if __name__ == "__main__":
# Recognize speech, generate response, and speak
while True:
print("\nListening...")
user_input = recognize_speech()
if user_input:
response_text = generate_response(user_input)
print("AI MondayAI:", response_text)
# Speak the response
speak(response_text)
I want to add so many things to it (I have already added to my OWN Monday), like personaltiton. but if i give you evertything at hand, will you learn anything? Also, if you’re looking for ideas to add, here’s something you can do:
- Make it more personal, by addind a dataset
- Make a dataset, that will add response from user and Gemini, and then send the gemini the data set along with the user input, that’ll be interesting to see!
And as always, contact me at penNpencil.foryou@gmail.con for any questions, or just comment in the comment section below.
I’ll see you next time, its Abhishek signing off